
「写真に写っている動物は犬か猫か」のように、2つの事象のどちらに属するかを予測する問題を、「二値分類」と言います。
本記事では、機械学習の基本的なアルゴリズムである「ロジスティック回帰」を用いて、二値分類問題に挑戦します。
目次
Udemyの動画学習でもPythonを勉強しよう!
「平日の夜の勉強会には時間が間に合わなくて参加できない」「通勤時間のわずかな隙間時間を勉強時間にあてたい」「本ではよく分からないところを動画で理解を深めたい」そんなあなたはUdemyの動画学習がお勧めです!
UdemyのPythonおすすめ33講座レビューリスト二値分類とは
・写真に写っている動物は犬か猫か
・顧客が商品を買うか買わないか
・Eメールがスパムかスパムでないか
のように、2つの事象のどちらに属するかを予測する問題のことです。
機会学習で二値分類をするための手法は、SVM、決定木、ニューラルネットワークなど複数あります。本記事では、ロジスティック回帰という手法を用いて二値分類を実装していきます。
ロジスティック回帰とは
ロジスティック回帰とは、ある事象が起こる確率を学習するためのアルゴリズムです。
この確率を利用して、ある事象が起こる / 起こらないという二値分類ができます。
例として、機械学習分野で有名な「タイタニック号の乗客が生存したかどうか」という二値分類問題を考えます。
この問題では、以下のような乗客のデータが与えられます。
| 名前 | 年齢 | 性別 | 客室の等級 | 生存したかどうか(0 or 1) |
| Jack | 62 | 男 | 1 | 1 |
| Jessica | 22 | 女 | 3 | 1 |
| Daniel | 18 | 男 | 3 | 0 |
| Andrew | 33 | 男 | 2 | 0 |
| Amelia | 31 | 女 | 3 | 1 |
なお、「生存したかどうか」というような分類したい変数のことを、「目的変数」と言い、性別や年齢などの周辺情報を「説明変数」、あるいは「特徴量」などと呼びます。
ロジスティック回帰では、説明変数を入力すると、目的変数として0から1の確率値を出力するようなモデルを学習することを目指します。
具体的には、「Jackという62歳男性が、等級1の客室に乗船していた場合、32%の確率で生存している」というイメージの予測ができるように、機械学習モデルを作成します。
ロジスティック回帰を数学的に説明すると、
説明変数をx、パラメータをwとして、
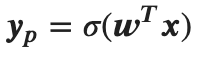
上記の式から計算される予測値ypと、目的変数yの二乗和誤差が小さくなるようにパラメータwを求める問題を解くことになります。
なお、式中に出てくる「σ」はシグモイド関数という関数であり、以下の数式で表されます。

グラフで表すと、以下のような図になります。

シグモイド関数の出力はグラフから読み取れるように0から1の値をとるため、説明変数xとパラメータwを元に計算された値を、0から1の確率値に収める役割を持ちます。
なお、シグモイド関数はロジスティック関数という関数の一部であり、そこからロジスティック回帰と名付けられました。
ロジスティック回帰を実装してみる
・データの準備(アヤメの品種)
今回用いるデータはアヤメの品種に関するデータです。pandasやmatplotlibといった外部ライブラリを使用するため、それらの理解が不安な方は、他の記事でライブラリの使い方を勉強しておきましょう。また、実行環境が整っていない方は、Google Colaboratoryなどのクラウドサービスの使用を検討してみてもよいでしょう。
まずは、データを準備して表で表示してみましょう。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = sns.load_dataset('iris')
display(data.head())(出力結果)
| sepal_length | sepal_width | petal_length | petal_width | species | |
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5 | 3.6 | 1.4 | 0.2 | setosa |
表の各項目は、以下を表しています。
・sepal_length: がく片の長さ
・sepal_width: がく片の幅
・petal_length: 花弁の長さ
・petal_width: 花弁の幅
・species: アヤメの品種
今回の実装では、アヤメの品種について二値分類を試します。どんな品種があるかは以下のコードで確認できます。
print(data['species'].unique())(出力結果)
['setosa' 'versicolor' 'virginica']setosa、versicolor、virginicaの3品種があることがわかりました。二値分類をするために、元のデータをsetosaとversicolorの2品種のみに絞っておきます。なお、ロジスティック回帰では文字列データは扱えないため、setosa = 0、versicolor = 1と置き換えておきます。
data = data.query('species in ["setosa", "versicolor"]')
data['species'] = data['species'].map({'setosa':0, 'versicolor':1})
print('データ数', len(data))
print('品種一覧', data['species'].unique())(出力結果)
データ数 100
品種一覧 [0 1]これでデータの準備は完了です。
・データの可視化
データを学習する前に、データの中身を詳しく確認しておきましょう。
まずは、データの型や欠損値の有無を確認します。
data.info()(出力結果)
<class 'pandas.core.frame.DataFrame'>
Int64Index: 100 entries, 0 to 99
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 100 non-null float64
1 sepal_width 100 non-null float64
2 petal_length 100 non-null float64
3 petal_width 100 non-null float64
4 species 100 non-null int64
dtypes: float64(4), int64(1)
memory usage: 4.7 KBspeciesはint型、それ以外の項目は全てfloat型であること、また、欠損していないデータが100個あることがわかります。
欠損値が含まれていたり、文字列データが含まれている場合はロジスティック回帰で学習ができませんので、あらかじめデータを整形しておく必要があります。
続いて、各項目の統計量を確認します。
data.describe()(出力結果)
| sepal_length | sepal_width | petal_length | petal_width | species | |
| count | 100 | 100 | 100 | 100 | 100 |
| mean | 5.471 | 3.099 | 2.861 | 0.786 | 0.5 |
| std | 0.641698 | 0.478739 | 1.449549 | 0.565153 | 0.502519 |
| min | 4.3 | 2 | 1 | 0.1 | 0 |
| 25% | 5 | 2.8 | 1.5 | 0.2 | 0 |
| 50% | 5.4 | 3.05 | 2.45 | 0.8 | 0.5 |
| 75% | 5.9 | 3.4 | 4.325 | 1.3 | 1 |
| max | 7 | 4.4 | 5.1 | 1.8 | 1 |
最大値、最小値、平均値、標準偏差といった統計量が確認できます。統計量を確認することで、精度良く機械学習を行うためのヒントを得ることができます。
続いて、各項目の分布を確認します。
for col in data.columns:
print(col)
plt.hist(data[col], bins = 10)
plt.show()(出力結果)
sepal_length

sepal_width

petal_length
petal_width
species

分布を確認し、明らかに他のデータから離れたデータ(外れ値)があれば、消去するなどの対応が必要になることがあります。
続いて、項目ごとの相関を確認します。
| sns.pairplot(data, hue=’species’) plt.show() |
(出力結果)
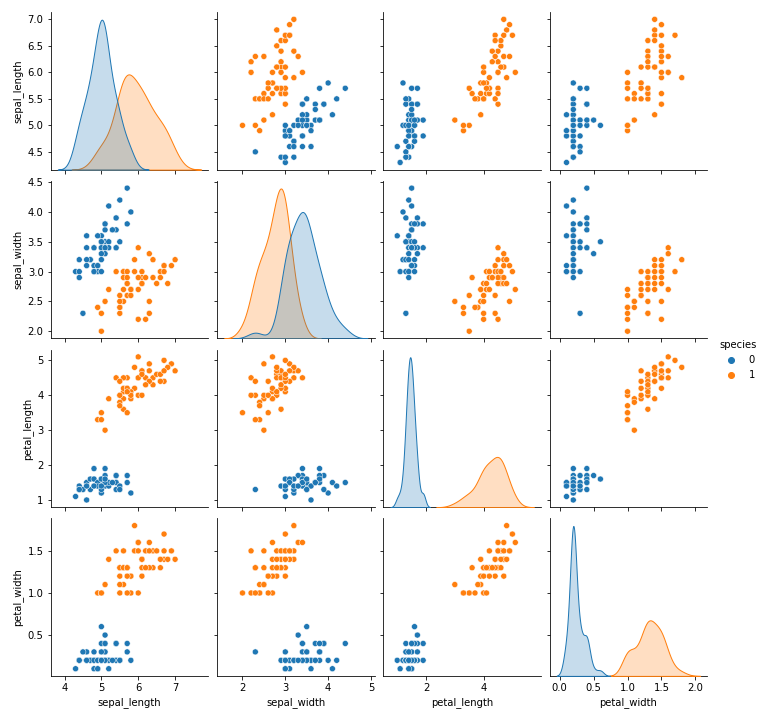
グラフを確認すると、アヤメの種類別で明らかに特徴に違いがありそうなことがわかります。
例えば、グラフの左下の領域を確認すると、種類0(setosa)のアヤメは、花弁の長さ(petal_length)とがく片の長さ(sepal_length)が短い、種類1(versicolor)のアヤメは、どちらの特徴も長いことが読み取れます。
以上のように、データを可視化してみることは機械学習において非常に重要です。
・実装
実装は、sklearnという機械学習ライブラリを用いれば非常に簡単です。
実装コードは以下のようになります。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 説明変数と目的変数に分ける
X = data.drop(['species'], axis=1)
Y = data['species']
# 訓練データと検証データを0.75:0.25に分ける
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size = 0.25, random_state = 0)
# ロジスティック回帰で学習する
model = LogisticRegression()
model.fit(X_train, Y_train)データは、ロジスティック回帰モデルを学習するための「訓練データ」と、モデルの精度などを評価するための「検証データ」に分けておく必要があります。
sklearnライブラリを使うと、LogisticRegression()の一行でモデルを作成でき、fit()メソッドで訓練データに最適化するようモデルが学習されます。
なお、モデルを学習するということは、数学的には以下の数式のパラメータwを求めることと同じです。
どんなパラメータが求まったかは、以下のコードで確認することができます。
print("coefficient = ", model.coef_) # パラメータwの係数ベクトル(w1, w2, w3...)
print("intercept = ", model.intercept_) # 切片(w0)(出力結果)
coefficient = [[ 0.37461321 -0.83919799 2.17585467 0.91900489]]
intercept = [-6.06168563]モデルが学習できた後は、「未知のアヤメのデータ」に対して「どの種類のアヤメか?」を予測することができます。
例えば、以下のような検証データに対して、
display(x_test.head(3))(出力結果)
| sepal_length | sepal_width | petal_length | petal_width | |
| 26 | 5 | 3.4 | 1.6 | 0.4 |
| 86 | 6.7 | 3.1 | 4.7 | 1.5 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
predict()メソッドを使うと、予測結果を出力することができます。
y_pred = model.predict(x_test)
print(y_pred[:3])(出力結果)
[0 1 0]これは、検証データの1行目は種類0のアヤメ、検証データの2行目は種類1のアヤメ、検証データの3行目は種類0のアヤメと、機械学習モデルが予測していることを表します。
実際に検証データの目的変数がどのような値だったかを確かめると、予測が正しいことがわかります。
y_test.head(3)(出力結果)
26 0
86 1
2 0
Name: species, dtype: int64モデルの性能評価には、検証データの精度(モデルの予測と、実際の正解との一致率)などで判断することが一般的です。
from sklearn.metrics import accuracy_score
print('accuracy_score:', accuracy_score(y_test, y_pred))(出力結果)
accuracy_score: 1.0検証データに対しては正解率100%であることがわかりました。
今回使用したデータは非常に単純なデータであるため、100%の正解率となりましたが、実務などで用いる複雑なデータで高い精度を達成するためには、データの前処理を工夫したり、様々なアルゴリズムを試したりする必要があるでしょう。
まとめ
・2つの事象のどちらに属するかを予測する問題を「二値分類」と言い、「ロジスティック回帰」を用いて二値分類問題を解くことができる。
・ロジスティック回帰は、ある事象が起こる確率を学習するためのアルゴリズムであり、シグモイド関数と呼ばれる0から1の確率値を出力する関数が特徴的。
・データを準備したらすぐに機械学習を行うのではなく、データの型や分布を図示して、どんなデータであるかを確認することが重要。
・ロジスティック回帰の実証には、sklearnなどの機械学習ライブラリを用いると簡単に実装することができる。
・モデルの性能評価には、検証データに対する正答率を見ることで測ることができる。
Udemyの動画学習でもPythonを勉強しよう!
「平日の夜の勉強会には時間が間に合わなくて参加できない」「通勤時間のわずかな隙間時間を勉強時間にあてたい」「本ではよく分からないところを動画で理解を深めたい」そんなあなたはUdemyの動画学習がお勧めです!
UdemyのPythonおすすめ33講座レビューリスト